 Learning to predict single-wall carbon nanotube-recognition DNA sequences (机器学习预测单壁碳纳米管识别的DNA序列)
Learning to predict single-wall carbon nanotube-recognition DNA sequences (机器学习预测单壁碳纳米管识别的DNA序列)
Yoona Yang, Ming Zheng & Anand Jagota
npj Computational Materials 5:3 (2019)
doi:s41524-018-0142-3
Published online:10 January 2019
Abstract| Full Text | PDF OPEN
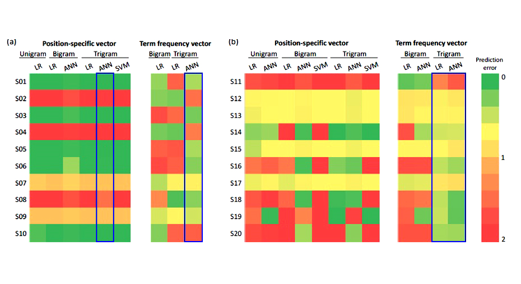
摘要:DNA 具有分散和筛选不同手性和偏手性的单壁碳纳米管的特性,这将带来诸多应用。为寻找能够筛选任一给定类型碳管的DNA序列,人们已经开展了大量工作,并在理解DNA/碳管复合物结构及热力学方面取得了很大进展。然而,从头预测识别序列的方法尚难以实现,而且通过搜索巨大的单链DNA库来寻找序列的成功率非常低。本研究提出了一种通过机器学习现有实验序列数据集来预测识别序列的有效方法。采用了多种输入特征构造法(位置特定、时期频率、组合或分段术语频率向量,以及基于基序的特征),并进行了比较。利用转换后的特性训练了几种分类算法(逻辑回归、支持向量机器学习和人工神经网络)。采用训练过的模型预测新的识别序列集,并以多个模型之间的一致性成功抵消数据集规模不够的限制。采用水性两相分离法测试了预测的准确性。将实验测试过的新预测序列数据集进一步添加到原始数据集,以此新获取的数据重新训练模型。基于训练模型识别出序列的正确率,相比原始训练数据集训练模型大幅提升,从~10%提高到>50%。
Abstract:DNA/single-wall carbon nanotube (SWCNT) hybrids have enabled many applications because of their special ability to disperse and sort SWCNTs by their chirality and handedness. Much work has been done to discover sequences which recognize specific chiralities of SWCNT, and significant progress has been made in understanding the underlying structure and thermodynamics of these hybrids. Nevertheless, de novo prediction of recognition sequences remains essentially impossible and the success rate for their discovery by search of the vast single-stranded DNA library is very low. Here, we report an effective way of predicting recognition sequences based on machine learning analysis of existing experimental sequence data sets. Multiple input feature construction methods (position-specific, term-frequency, combined or segmented term frequency vector, and motif-based feature) were used and compared. The transformed features were used to train several classifier algorithms (logistic regression, support vector machine, and artificial neural network). Trained models were used to predict new sets of recognition sequences, and consensus among a number of models was used successfully to counteract the limited size of the data set. Predictions were tested using aqueous two-phase separation. New data thus acquired were used to retrain the models by adding an experimentally tested new set of predicted sequences to the original set. The frequency of finding correct recognition sequences by the trained model increased to >50% from the ~10% success rate in the original training data set.
Editorial Summary
Machine Learning: Predicting DNA Sequences for recognizing carbon nanotubes(机器学习:预测识别单壁碳纳米管的DNA序列)
该研究采用机器学习系统地预测了可识别特定单壁碳纳米管的DNA序列。来自美国Lehigh大学化学与生物分子工程系的Anand Jagota等,基于现有实验序列数据集,报告了一种用机器学习分析来预测识别DNA序列的有效方法。为便于分析、解释,他们将SWCNT识别的DNA序列限制为只有2种碱基组合(C&T)的、12个碱基构成的短序列。以已知数据训练机器学习模型,并将实验测试过的新序列数据集添加到原始数据集,重新训练模型。通过交叉验证和新测试集上的预测误差来评估预测性能,并通过特征表示方法改进模型性能。结果显示准确预测识别序列的频率从原始训练集的10%显着提升到> 50%。他们所获得的机器学习模型,有可能为更普遍的序列选择问题提供新的途径。
Now, DNA sequence for recognizing single-walled carbon nanotube (SWCNTs) in DNA/SWCNT hybrid systems can be systematically predicted using machine learning (ML). A team lead by Anand Jagota from the Department of Chemistry and Biomolecular Engineering at Lehigh University in the United States reported an effective method for predicting recognition sequences using machine learning analysis based on existing experimental sequence data sets. For ease of analysis and interpretation, they restricted the SWCNT recognition sequence to a short sequence of 12 bases with only 2-base (C & T) combinations. ML models were trained on available data, and retrained twice based on new experimental data. Cross-validation and prediction error were used to evaluate the new test set and feature representation methods were selected to improve the model performance. The results show that the frequency of accurate prediction recognition sequences is significantly increased from 10% of the original training set to > 50% of the ML prediction sequence set. The ML model may has the potential to provide new avenues for overcoming more general sequence selection problems.

 沪公网安备 31010502006565号
沪公网安备 31010502006565号